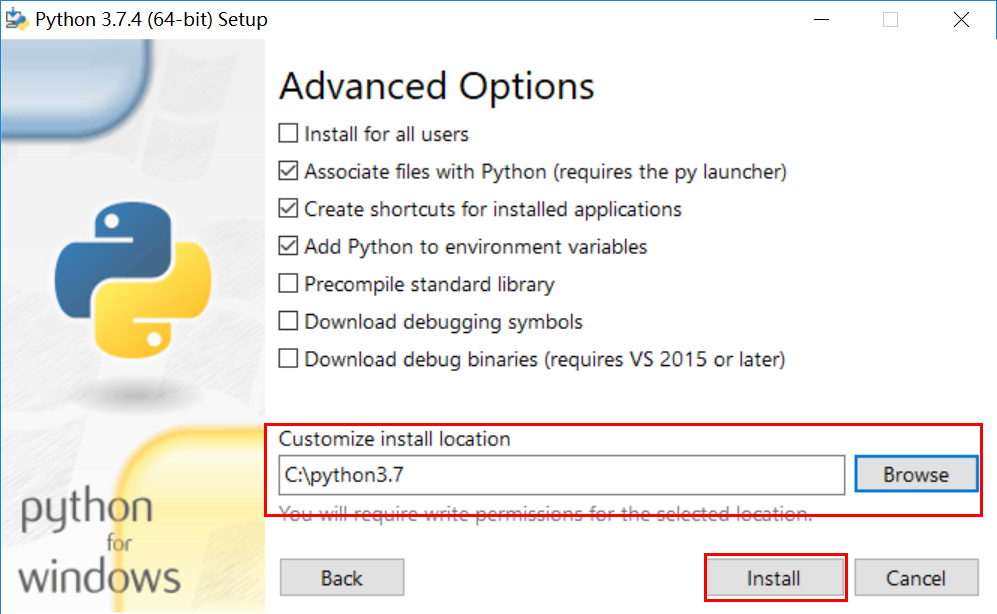
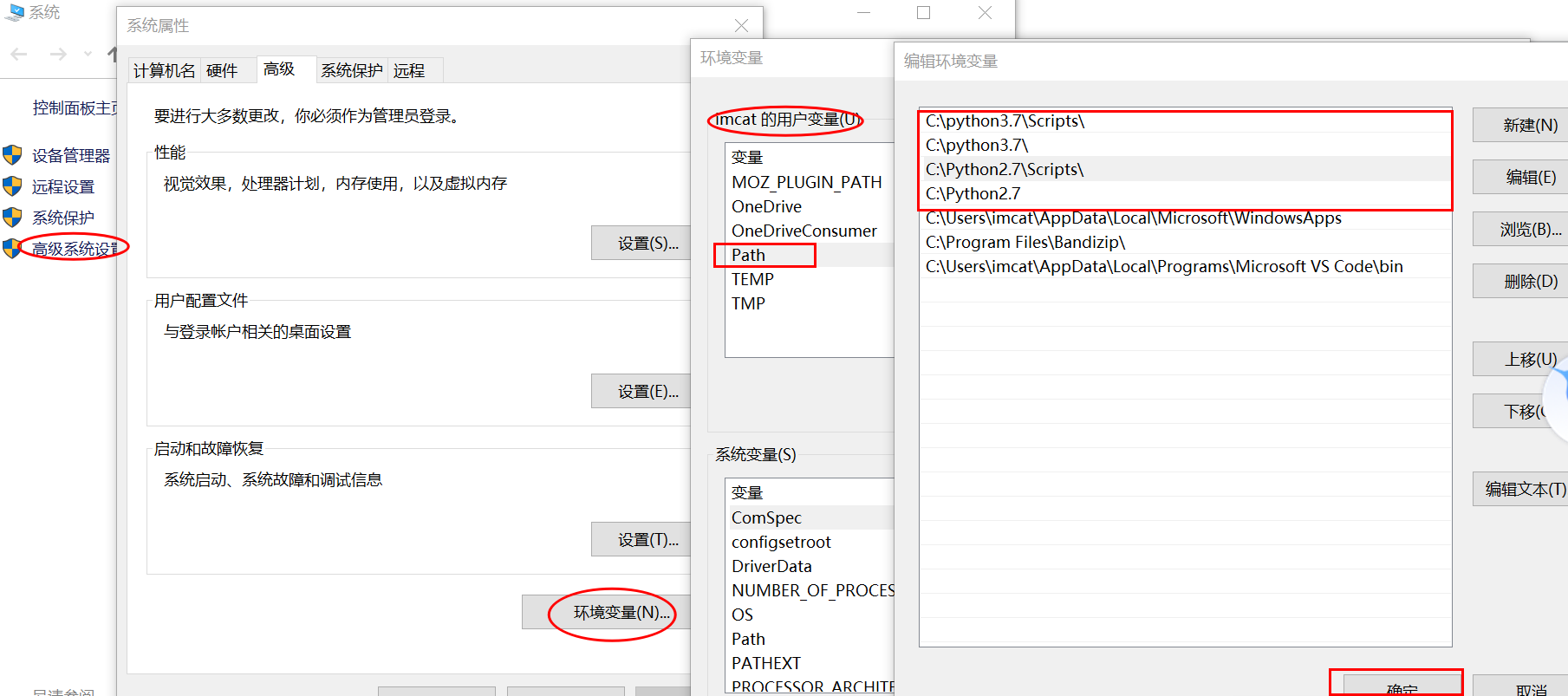
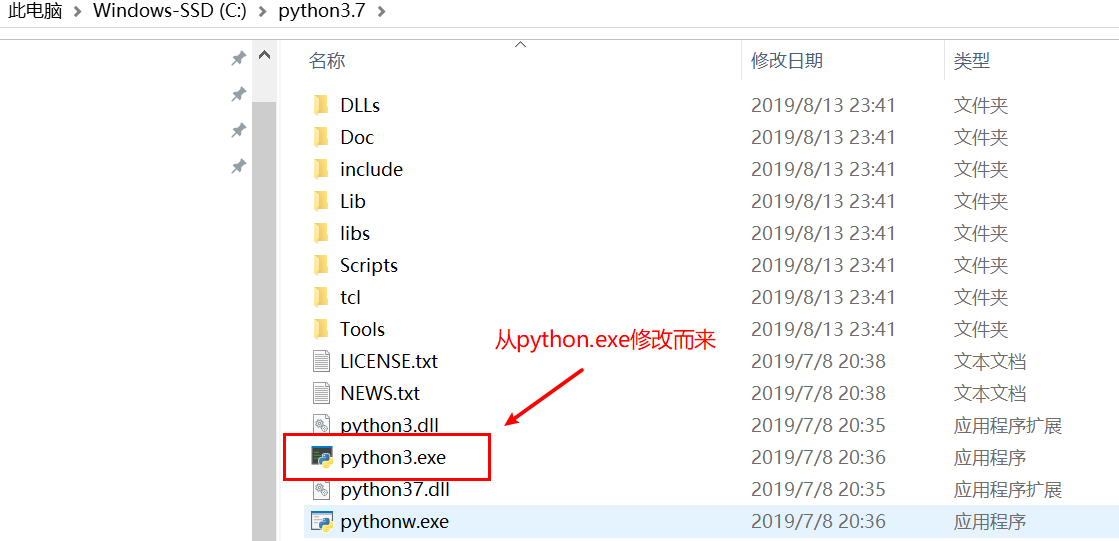
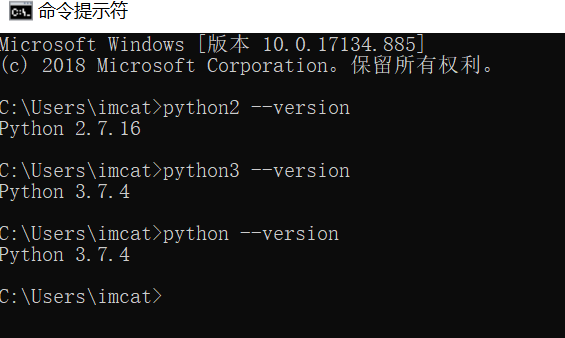
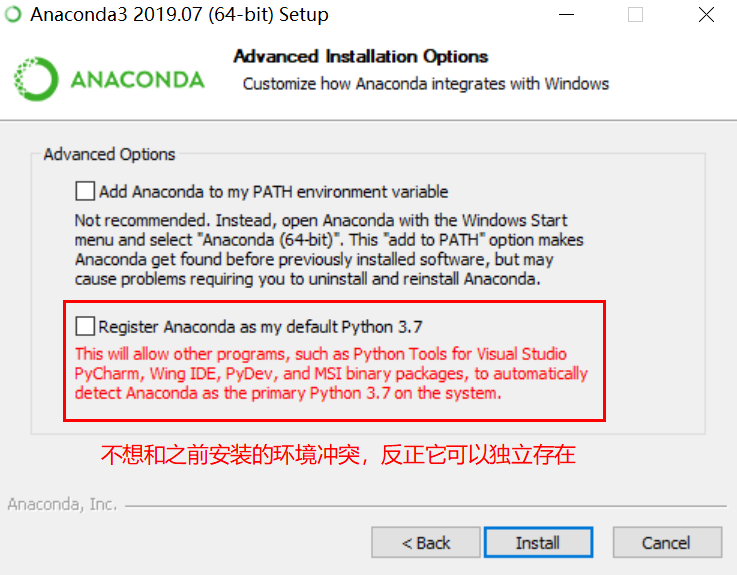
staticvoidtest_entry_01(int a, int b){ if (a) if (b) printf("%s> b if\n", __func__); else printf("%s> b else\n", __func__); else printf("%s> who am I ? # a if ??? yes\n", __func__); }
staticvoidtest_entry_02(int a, int b){ if (a) if (b) printf("%s> b if\n", __func__); else { printf("%s> a else ? no I'm b else.", __func__); // no new line printf("more info...\n"); } else printf("%s> who am I ? # I'm a else.\n", __func__); }
staticvoidtest_entry_03(int a, int b, int c){ if (a) printf("%s> nothing to be done...\n", __func__); if (b) printf("%s> b if, but not nest in a.\n", __func__); else printf("%s> b else ? yes\n", __func__); if (c) printf("%s> who am I? I don't belong to any of the control blocks above.\n", __func__); else printf("%s> who am I? I'm c else.\n", __func__); }
intmain( int argc, char **argv){
int a, b, c; if (argc != 4) { printf("Usage: <APPNAME> a b c\n"); return0; }
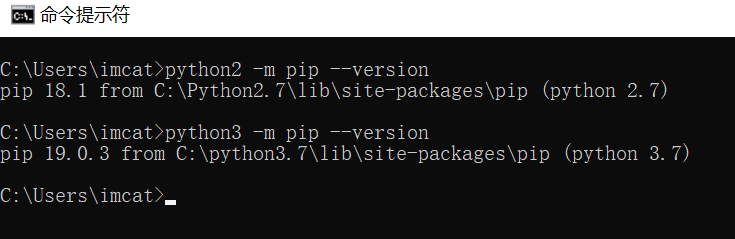
$ gcc -o test ./test_else.c $ ./test > Usage: <APPNAME> a b c $ ./test 1 1 1 > a=1, b=1, c=1 test_entry_01> b if test_entry_02> b if test_entry_03> nothing to be done... test_entry_03> b if test_entry_03> who am I? I don't belong to any of the control blocks above.
if (!do_it_01(cond)) { printf("do_it_01 err ? do some thing.\n"); return-1; } elseif (!do_it_02(cond)) { printf("do_it_02 err ? do some thing.\n"); return-2; } elseif (!do_it_03(cond)) { printf("do_it_03 err ? do some thing.\n"); return-3; } elseif (!do_it_04(cond)) { printf("do_it_04 err ? do some thing.\n"); return-4; } else { if (exception){ deal_exception(); return-5; } else { printf("default..., do some process..\n"); } }